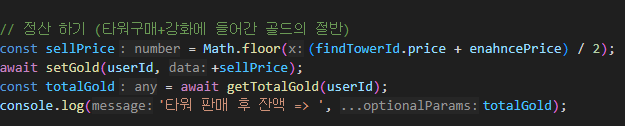
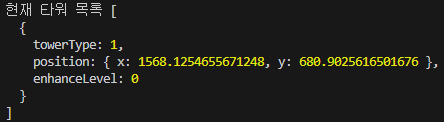
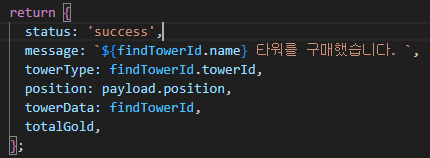
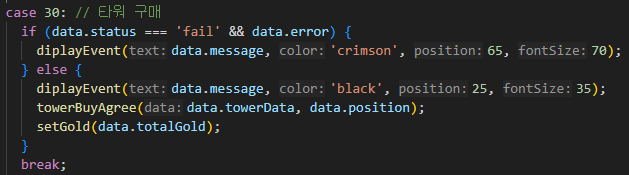
첫 주차에 간략히 배웠던 TCP를 본격적으로 시작한다.
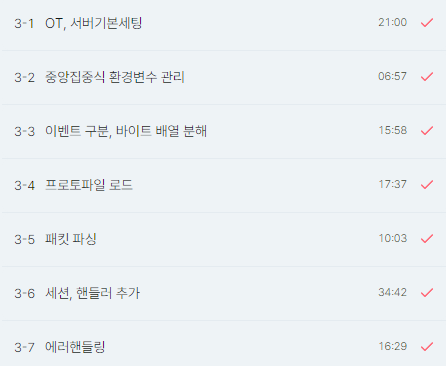
오늘 학습한 내용은 위와 같으며,
강의 하나 하나의 난이도가 상당하다.
하나에 20분 내외로 끝날 강의가 맞을까 의심이 되는데,
그럴것도 없이, 추가적인 학습을 유도하는 강의로 보인다.
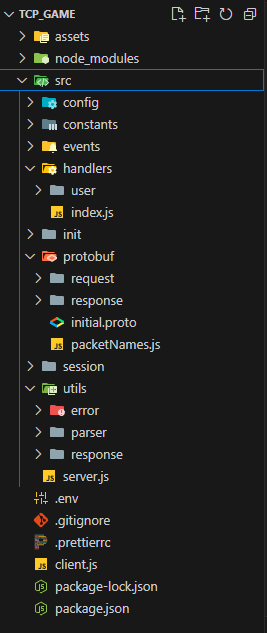
시작은 디렉토리 구조 부터 !
지난 과제의 디렉토리보다 세분화되어 복잡해 보인다.
아니, 익숙하지 않다고 하는게 더 맞는 말 같다.
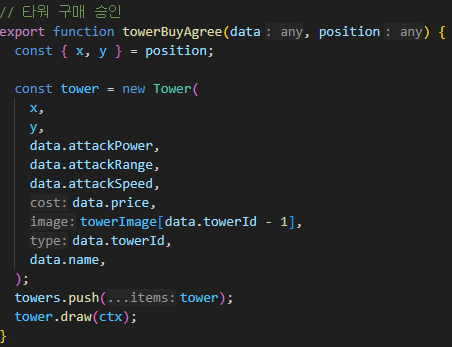
server.js 를 시작으로

무려 Node 의 기본 모듈

net 을 이용하여 TCP 서버를 생성하고
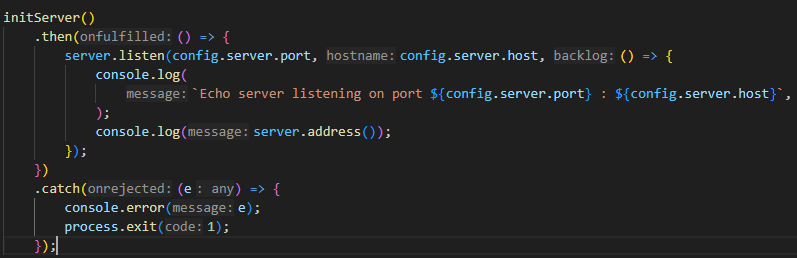
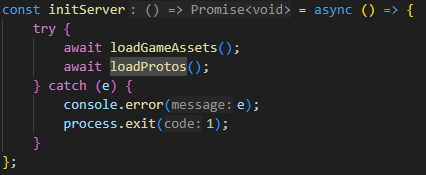
initServer 를 통해 본격적으로 서버가 구동된다.
기본적인 구조는 socket 서버의 형태와 크게 다르지 않지만,
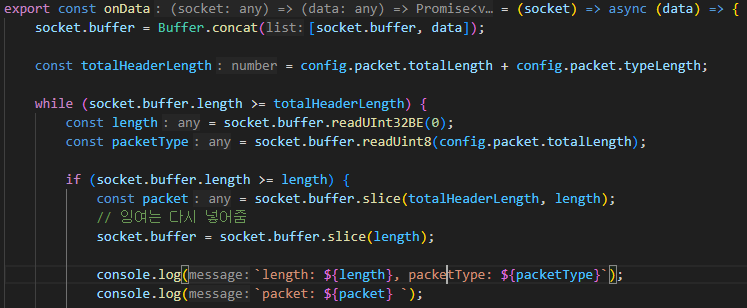
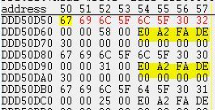
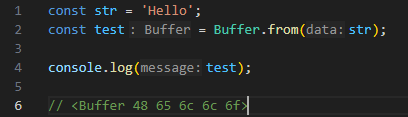
데이터를 주고 받을때는 반드시 buffer 의 형태 여야 한다는 것 !!
때문에, onData => 데이터를 받았을 때
당연히 buffer 형태로 왔을 것이므로, 해당 buffer를 다시 해석하는 과정이 필요하다.

에서 끝나면 사실 그렇게 복잡할 일은 아니다...

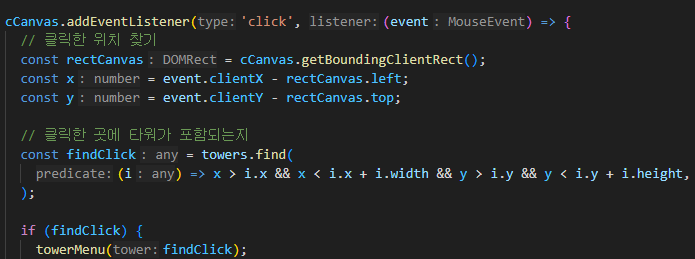
버퍼가 늘 출발한 순서대로,
예상한 시간에 도착하여 딱 딱 완성된다는 보장이없다.
따라서, while 반복문으로 헤더에 담긴, 오기로 한 길이만큼 올 때 까지 기다려 주는 상황을 만드는
코드가 필요하다.
버퍼들이 도착하여 이미 약속된 패킷의 길이가 될 때 까지 기다리는 것이다.
에서 끝나면 사실 그렇게 복잡할 일은 아니다...

해당 버퍼를 처리하려고 할 때, 추가적인 다른 버퍼들이 이미 도착해 있을 수 있다.
따라서, header 에 담긴 length 만큼만 buffer 에서 잘라서 처리하고,
나머지 부분은 다시 buffer 에 넣어버리는 코드를 작성한다.

여기가 3-3에 해당하는 내용인데,
이번 과제는 시작조차 쉽지가 않을것 같다.
'내일배움캠프' 카테고리의 다른 글
| 24.10.24 TIL 삼각함수 (0) | 2024.10.30 |
|---|---|
| 24.10.24 TIL 위치 동기화 (0) | 2024.10.24 |
| 24.10.18 TIL 버퍼 객체 (0) | 2024.10.18 |
| 24.10.17 TIL 검증이 뭘까 (0) | 2024.10.17 |
| 24.10.16 TIL 타워 디펜스 프로젝트 -완- (0) | 2024.10.16 |