상당히 골치아픈 문제가 나와서 글로 작성해 보았다.
이게 level 1 이라니...
얼핏보면 수월하게 풀 수 있을것 같은 문제지만 (그렇게 생각했었는데요...)
제한 사항을 보면 X와 Y의 길이가 최대 300만 으로 정해져 있으며,
이로 인해서 이중 for문 등을 사용하면 시간복잡도가 급증해 시간초과의 결과가 나오게 된다.
풀이 설계
1. X 와 Y 를 내림차 정렬을 한다.
2. X 와 Y를 맨 앞에서부터 비교하여 같을 경우 answer 에 추가
3. X[0] Y[0] 이 같지 않을 경우 둘 중 작은 값의 다음 index를 검사
4. "0" 의 결과와 "-1" 의 결과를 따로 리턴
늘 그렇지만, 이번에도 대단히 효율적이진 않을것 같은 풀이 방향이다.
내림차 정렬을 위한 sort 2회, X와 Y의 값을 비교하기 위한 반복문이 기본적으로 필요하기 때문.
풀이 시작
X= [...X].sort((a,b) => b-a)
Y= [...Y].sort((a,b) => b-a)
시작은 역순정렬 부터 한다. 큰 값으로 정렬하여 비교하면 유리할 거라는 생각이었으나,
사실, sort 과정 자체가 시간복잡도를 많이 잡아먹어버린다.
어쨌든 그렇게 설계했기 때문에 이렇게 시작해 보도록 하자.
이 과정에서 저번 알고리즘 때 배웠던 [...str] 을 이용한 배열화를 사용해 보았다.
그 후, X와 Y를 비교하기 위해 반복문을 사용해야 하는데,
while 문을 사용하기로 했다.
let i = 0;
let j = 0;
while ( X.length > i && Y.length > j) {
if ( X[i] === Y[j]) {
answer += X[i]
j++
i++
}
X 와 Y의 끝까지 비교를 해야할 것으로 예상되기 때문에, 위 같이 조건을 주었고,
가장 중요한 X[i] ===Y[j] 일 경우 answer에 추가하는 것 까지는 어렵지 않게 진행되었다.
잘못된 풀이..?
그 전에, 잠깐 뻘짓을 했던 과정을 살펴보자면
while ( X.length > i && Y.length > j) {
if ( X[0] === Y[0]) {
answer += X[0]
X= X.substring(1)
Y= Y.substring(1)
}
위처럼 동일한 조건으로 진행하지만, i j 를 통해 다음 index로 넘어가는것이 아니라,
.substirng(1) 을 통해 X,Y의 0번의 index만 검사하도록 진행해 보려는 시도를 했었는데,
굳이 substring 이라는 메서드가 사용된다는 점 때문에 폐기 되었다.
시도했던 이유와 폐기한 이유??
substring 은 문자열의 0번째 ~를 제거하는 메서드이다.
참조형이 아닌 기본형 타입의 string을 변조하는건 시간복잡도가 1회 일 것으로 예상을 했었으나,
기본적으로 substring() 의 시간 복잡도는 O(n) 에 해당했다.
글 마무리에 substring을 사용했을 때와, index 순번을 사용했을 때의 시간차이를 비교해보도록 하겠다.
자, 다시 풀이로 돌아와서, 이제 X[i] 와 Y[j] 가 다른 값일 경우만 처리하면 된다.
생각이 닿기는 좀 시간이 걸렸지만,
while ( X.length > i && Y.length > j) {
if ( X[i] === Y[j]) {
answer += X[i]
j++
i++
} else if (X[i] > Y[j]){
i++
} else {
j++}
}
X[i] 와 Y[j] 의 둘 중 큰 값을 비교해서
큰 값을 가진쪽의 index 를++ 해서 다음 index를 참조하게 하면,
점점 값이 작아지며 서로 같은 값이 나올때 까지 넘어가게 된다.
마무리로,
if (answer[0] === "0" ) { return "0"}
return answer === ""? "-1" : answer
"000000" 만 나온 경우와 일치하는값이 하나도 없을경우만 따로 빼주면 정답이 완성된다.
답 코드
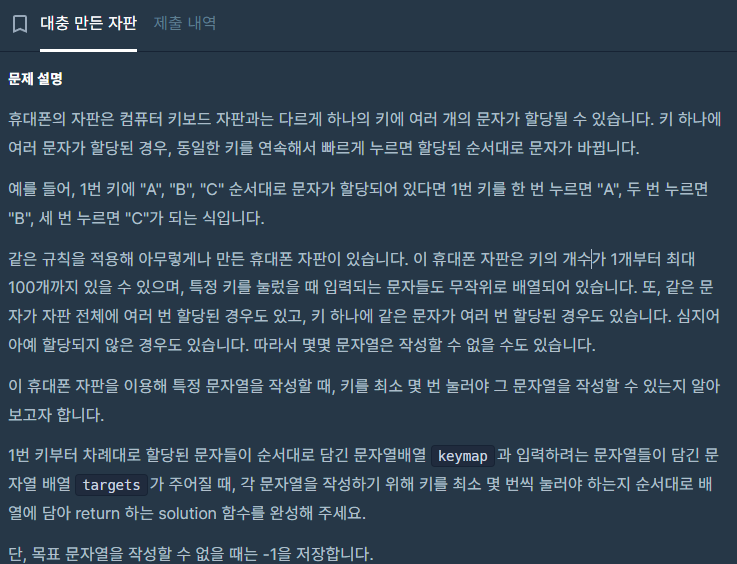
function solution(X, Y) {
var answer = '';
X= [...X].sort((a,b) => b-a)
Y= [...Y].sort((a,b) => b-a)
let i = 0;
let j = 0;
while ( X.length > i && Y.length > j) {
if ( X[i] === Y[j]) {
answer += X[i]
j++
i++
} else if (X[i] > Y[j]){
i++
} else {
j++}
}
if (answer[0] === "0" ) { return "0"}
return answer === ""? "-1" : answer
}
앞서 말한것 처럼, sort와 반복문이 사용되며 결론적으로 그렇게 효율적인 코드는 아니게 되었다.

딱 봐도 11~ 15번 case 가 헬 구간 ( X,Y length가 길게 주어지는듯)
그렇다면, substirng 의 경우 얼마나 차이가 날까?
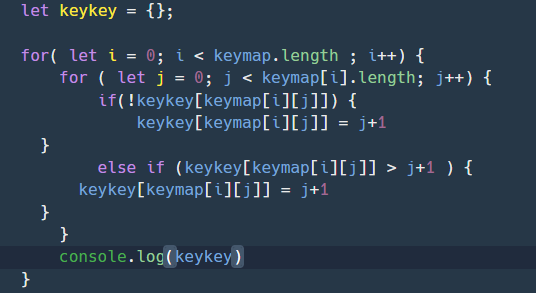
function solution(X, Y) {
var answer = '';
X= [...X].sort((a,b) => b-a).join('')
Y= [...Y].sort((a,b) => b-a).join('')
while ( X.length > 0 && Y.length > 0) {
if ( X[0] === Y[0]) {
answer += X[0]
X= X.substring(1)
Y= Y.substring(1)
} else if (X[0] > Y[0]){
X= X.substring(1)
} else {
Y= Y.substring(1)}
}
if (answer[0] === "0" ) { return "0"}
return answer === ""? "-1" : answer
}
.substirng(1) 이기 때문에 별로 차이가 없지 않을까 하는 생각에서 완성을 해 보았다.

유의미한 차이가 있다.
substirng(1) 이라고 해도 결코 상수의 처리시간이 걸리는건 아닌것으로 보인다.
물론 X 와 Y를 추가로 join 해주는 과정에서도 추가적인 시간이 소요됐겠지만 말이다.
대충 정리를 하자면
11~15번 케이스에서 걸린 시간은
기본 답 코드 ( X[i] Y[j] 로 비교) = 약 2300ms 가량
두 번째 테스트 ( 기본 답 코드에서 X,Y를 join만 해준 경우) = 약 2500ms 가량 (join에 걸리는 시간 대략적으로 확인)
세 번째 테스트 ( join 이후 substring을 통해 X[0] Y[0] 으로 비교) = 약 2800ms 가량 ( join과 substring에 걸리는 시간 확인)
당연히~~~~~
X[i] Y[j] 로 비교하는것이 빠르겠지만, 순전히 궁금증이 생겨나서
테스트를 해 보게 되었다.
결론은.... 애초에 sort 가 제일 오래 걸리는듯 함 (ㅠ)