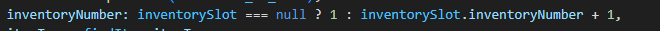추석 연휴 기간동안에도 팀 과제를 진행했지만, 따로 TIL에 기재하지는 않았다.

저번 TIL 에서도 말했지만, 모든 휴일과 제출당일을 제외하면 4일밖에 남지 않았기 때문에 (그 중 하루는 오늘 !!)
팀원들과 상의해서 연휴 기간에도 모여서 프로젝트를 진행하기로 했었다 .

현재, 내게 주어진 임무 중, 필수기능에 해당하는 부분은 모두 구현이 완료가 된 상태이다.

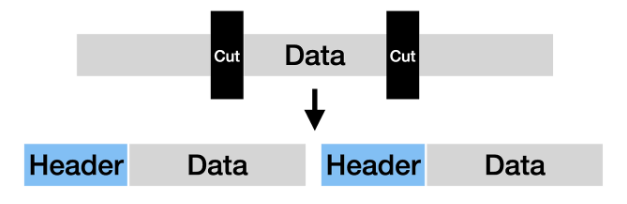
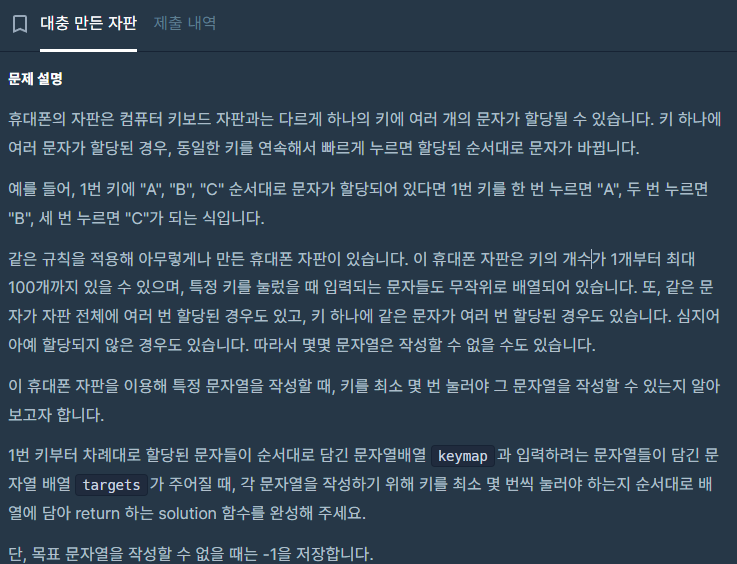
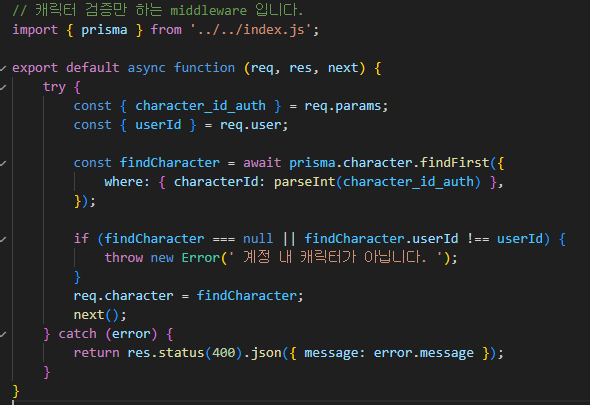
다만, 현재의 roster 테이블의 구성은, 위 그림에서 보는것과 같이
rosterId (PK) , 계정ID, 선수 Id 로 이루어진 일종의 인벤토리 테이블로 되어있다.
데이터 1개 (행) 당 1개의 선수만을 표시하므로, 선수가 쌓일수록 데이터가 굉장히 많아지는 구조이며,
이 형태는 내가 직전 과제인 CH3 아이템시뮬레이터 에서 작성했던 인벤토리 테이블과 정확히 일치하는 구조이다.
여기서 !!
차선책 이었던 위 형태의 라이벌이 되는 구조가 있었는데,
그것은 수량 개념 을 갖는 컬럼을 만들고, 데이터 한개가 여러개의 동일한 선수를 보유하고 있음을 표현하는 방식이다.
수량 개념이 있다면 동일 데이터에서 수량만 변할것이므로 사실상 accountId 와 playerId가 일종의 1:1 관계가 되고
데이터의 숫자가 확연히 줄어들게 되므로 장점이 많다.

그럼 왜 해당 방법을 버리고 데이터가 우후죽순 늘어나는 방법을 채택했는가...?
그 이유는

선수 강화 기능에 대한 고려를 한 결과이다.
선수 강화를 적용하는 방식은 크게 두 가지로 나눌 수 있다.
첫 번째 방법
데이터 베이스에 해당 선수의 강화 결과에 대한 데이터가 전부 넣어버린다.
예를 들면 player 테이블 내에
선수ID1 호날두 +0 공격력 90 수비력78 스태미나 84
선수ID2 호날두 +1 공격력 96 수비력 81 스태미나 86
선수ID3 호날두 +2 공격력 101 수비력 83 스태미나 90
위와 같은 강화 결과에 대한 데이터가 별도의 선수Id 로 '이미' 존재하고 있어야한다.
강화 성공 시, 선수 Id 자체가 변하는 결과가 되는것이다.
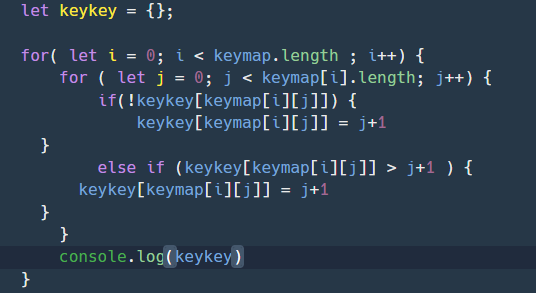
두 번째 방법

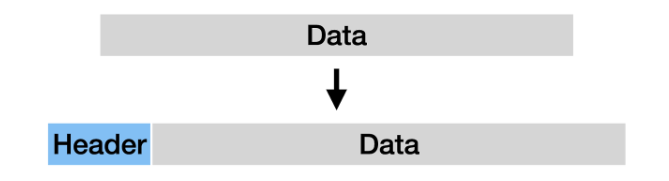
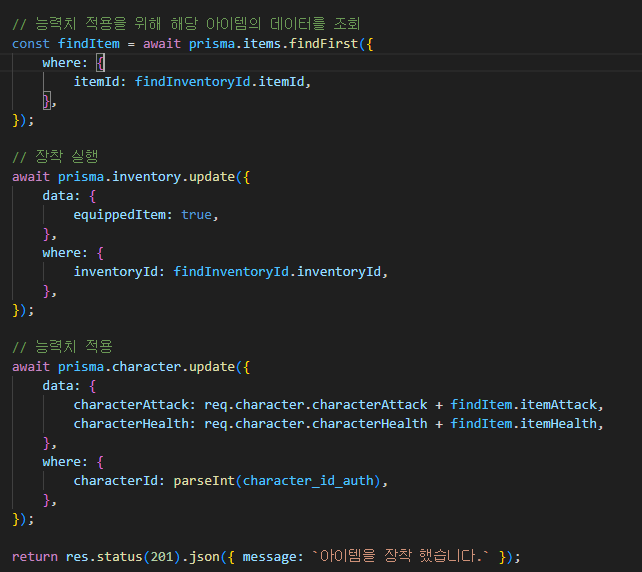
그림처럼, 선수 테이블에 enhanceCount 를 넣고 강화 수치를 표시해서,
별도로 강화 수치가 기록된 테이블의 데이터를 참고하여...
실제 강화된 능력치가 적용되어야 하는 순간에 해당 수치만큼
능력치를 더해서 적용하는 방법이다.
왜 그림 자료가 있는가 하면, 이 두 번째 방법을 사용중이기 때문이지 !!

아니 그럼 두 번째 강화 방법에 수량까지 추가하면 되는거 아닌가? 하는 의문이 생긴다.
그럴싸 하지만, 위 방법대로라면,
수량이 50으로 되어있는 데이터의 선수를 강화를 하면 50명이 전부 강화되는 일이 발생할 것이다.
이런 사태를 피하려면? ==> 강화 결과 선수 ID 자체가 변해야 한다. ===> 강화 결과 새로운 선수ID 필요
=== 위의 첫 번째 강화 방법이 필요
위 방법을 사용한다면, 선수 하나를 새로 등록하는데
5강화 까지만 데이터를 추가한다고 해도 6개씩의 데이터를 입력해야한다.
따라서, 1선수 1데이터라 해도 데이터가 우후죽순 늘어날 가능성이 희박한 환경(과제) 인 점,
굳이 +0 +1 +2 +3 +4+5 데이터베이스 노가다가를 할 필요가 없다는 점에서 !!!
본문 초반에 나온 roster 의 방식이 사용되었다고 할 수 있다.
해당 방식을 채택한 이유에 대한 설명은 여기까지 하고,
다음은 오늘 해결된 코드 내용을 간략히 설명해 볼까 한다.
해당 코드는, 내가 담당(부) 로 되어있는 선수 뽑기 ! gacha에 해당하는 부분이다.
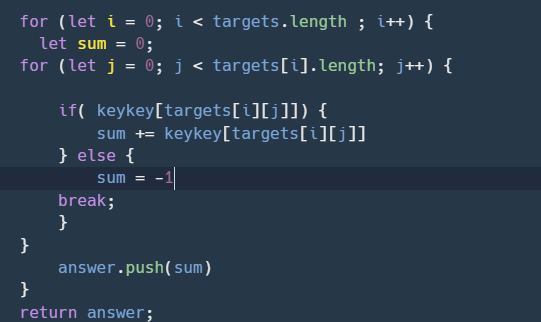
문제의 코드를 살펴보자.
// create 를 반복문으로 돌렸습니다...
const manyPlayer = async function aabb(accountId, gachaTry) {
// 가차 선수 범위
let answer = [];
for (let i = 0; i < gachaTry; i++) {
let randomPlayer = Math.round(Math.random() * (findMaximumPlayerId.playerId - 1)) + 1;
// 랜덤 선수 획득
const getGacha = await prisma.roster.create({
data: {
playerId: randomPlayer,
accountId: +accountId,
},
});가챠 기능 자체에 문제가 있던것은 아니지만,
위의 코드를 보면 누가 보기에도, create 가 반복문을 통해 돌아가는것은 바람직하지 않아보인다.
10번의 뽑기를 진행한다면,
prisma.roster.create 에 해당하는 부분이 10번이 반복되어버리는.... 매우 참담한 상황이다.

어느정도 해답에 가까운 정보를 검색을 통해서 알고있긴했지만....
바로 createMany prisma메서드를 사용하는 것이다.
문제는 createMany의 사용법이 너무 난해했기 때문에 접근을 전혀 하지 못하고 있었고...
튜터님을 통해 문제를 해결하기로 했다.

그 해답은 매우 심플했다....
createMany 사용법에서 알려주는것 처럼,
data 를 [] 배열... 즉 json 의 형태로 때려 넣어주면 알아서 다 생성한다는 것이다 !
마치 .map() 메서드의 실행 방식처럼 말이다.

위의 형태로 만든 뒤,
resultGacha 라는 변수가 가진값이 = [{playerId : 랜덤으로뽑힌number, accountId : 뽑기한유저ID}, {playerId ...}]
의 형태로 만들어 준다면, createMany가 정상적으로 작동하게 된다.
변수부분에 데이터를 잘 가공해서 넘겨줘야 하겠지만, 무려 반복문도 필요없고 2줄 분량의 코드로 줄어들었다.

여기서 answer = resultGacha 를 반환하는 함수를 따로 만들어줬고,
약간 조잡해 보이긴 하지만, create 전체를 반복문으로 돌리던 참담했던 과거와 비교했을 때,
무엇보다도 데이터 베이스를 조회하고 create 하는 횟수가 확연히 줄어들었다.
오늘도 문제 한가지 해결 !!

'내일배움캠프' 카테고리의 다른 글
| 24.09.13 TIL : CH3 풋살온라인 프로젝트 (0) | 2024.09.13 |
|---|---|
| 24.09.12 TIL : CH3 아이템 시뮬레이터 (0) | 2024.09.12 |
| 24.09.11 TIL : CH3 아이템 시뮬레이터 (0) | 2024.09.11 |
| 24.09.10 TIL : CH3 아이템 시뮬레이터 (0) | 2024.09.10 |
| [스탠다드 반]OSI 7계층 - 네트워크 계층 (0) | 2024.09.10 |