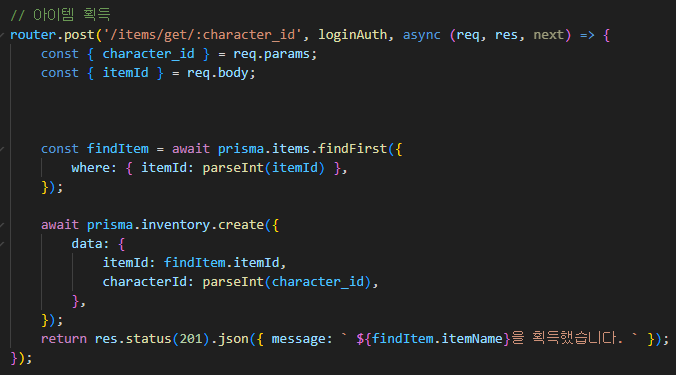
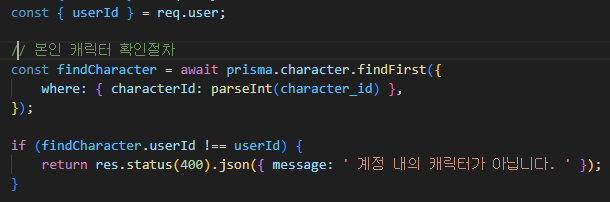
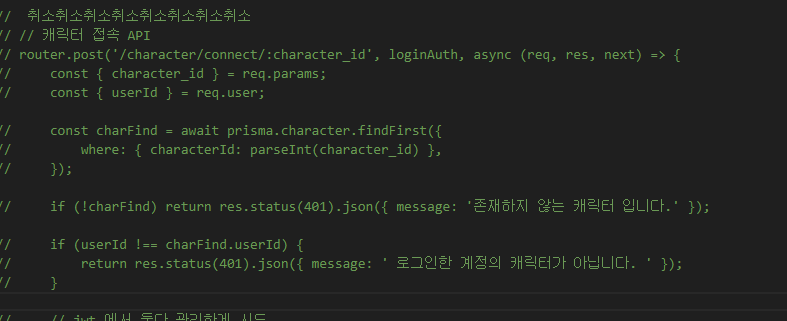
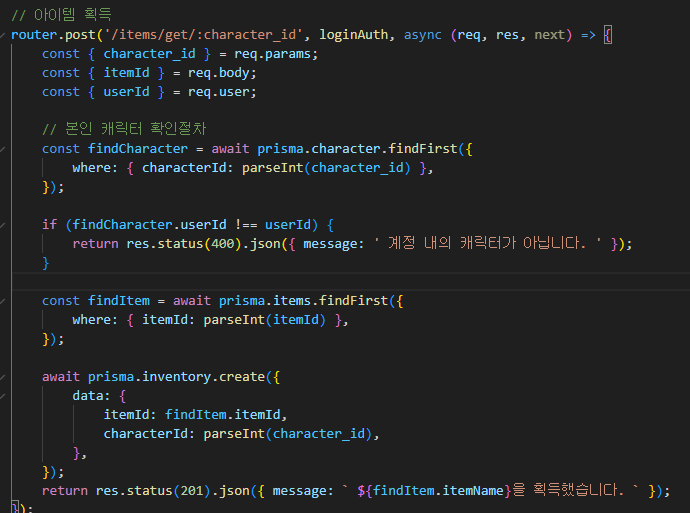
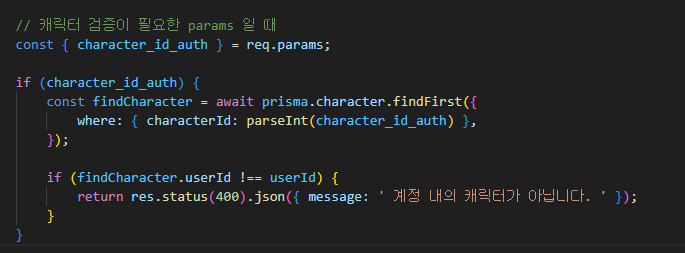
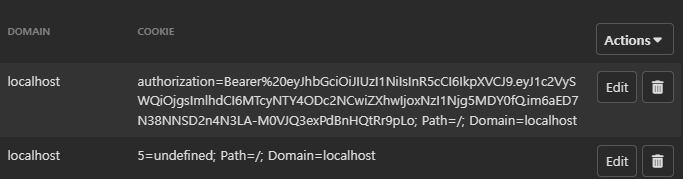
4. 전송 계층

앞서 배웠던 물리 계층, 데이터 링크 계층, 네트워크 계층으로만 구성이 되어도
데이터의 전송이 가능합니다. 그것도 최종 목적지 까지요 !
그러면 이름부터 '전송' 계층인 4계층은 무슨 역할을 하는걸까요?
전송 계층은, 데이터의 전송간에 패킷의 손실이나 오류 없이 올바른 순서로 도착하게 해주는 역할,
필요한 경우 데이터 패킷을 원활하게 복구하는 역할을 합니다.
쉽게 말해 ' 흐름 제어 ' 와 ' 오류 제어' 를 위한 계층이다! 라고 할 수 있습니다.
전송 계층하면, 빠질 수 없는 내용이 있는데,
그것은 전송계층의 프로토콜인 TCP 와 UDP 입니다.
TCP 란?
Transmission Control Protocol
안전 제일 !
TCP는 데이터 전송간에 손실이 거의 발생하지 않는 프로토콜 입니다.
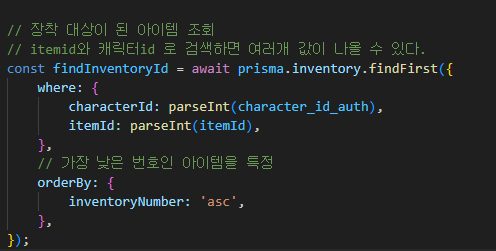
TCP의 통신 과정은 다음과 같습니다.
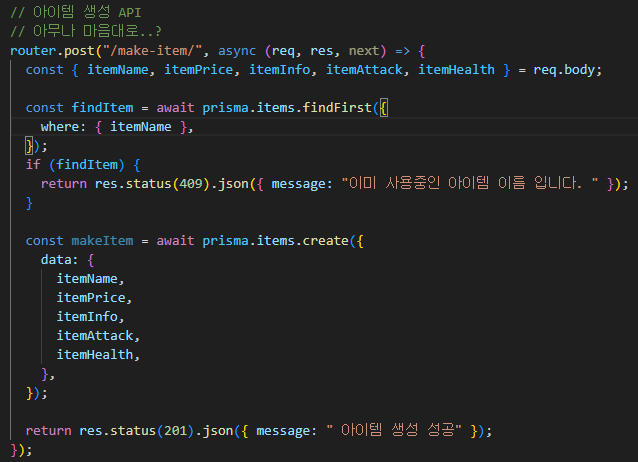
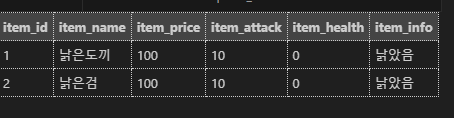
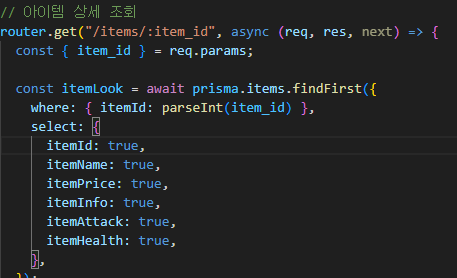
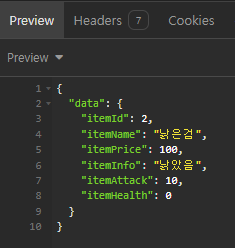
1. 데이터 스트림에서 받은 데이터를 일정 단위로 분할합니다 .
2. 분할된 데이터 단위에 TCP 헤더를 붙여서 TCP 세그먼트를 생성합니다.
3. TCP 세그먼트를 IP 데이터그램으로 변환합니다.
4. IP 데이터그램을 수신 어플리케이션에 보냅니다.
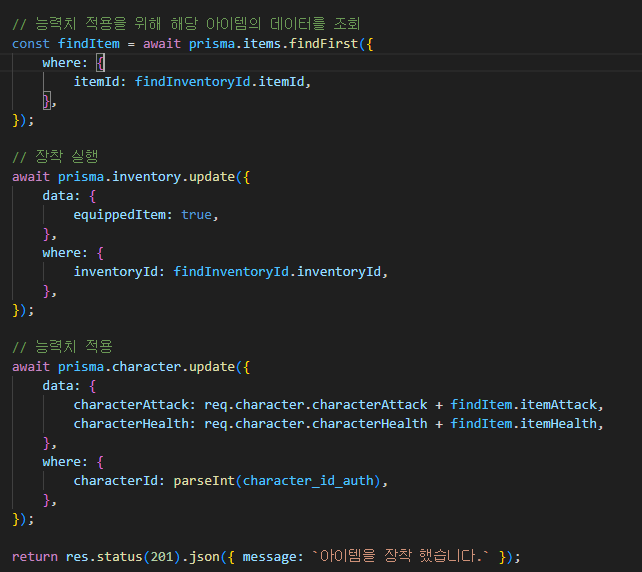
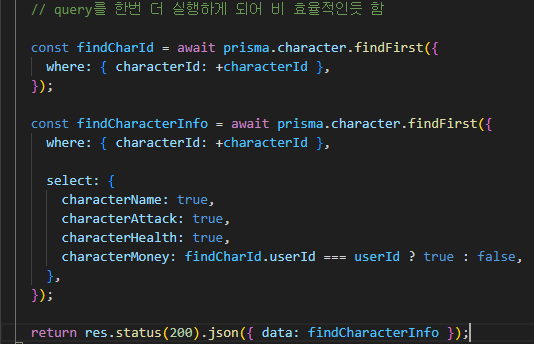
여기서 세그먼트 ! 는
TCP 가 데이터를 전송할때 사용하는 데이터의 크기 를 말합니다.
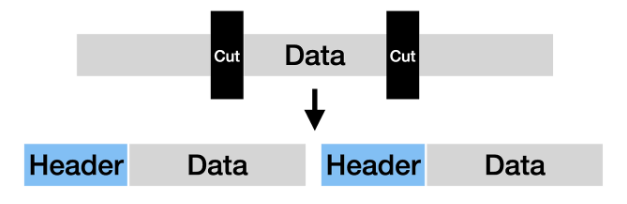
해당 이미지는 데이터를 일정 크기로 쪼개서 header 를 붙여서 세그먼트로 만드는것을 표현합니다.
이전에 배웠던
비트 bit => 1 계층
프레임 frame => 2계층
패킷 packet => 3계층
과 같이, 4계층 중 TCP 에서의 데이터 단위는 세그먼트 라고 할 수 있습니다.
아래 나올 UDP 의 경우는 datagram 단위를 사용하기 때문에,
같은 4계층이지만, TCP와 UDP는 서로 다른 데이터 타입을 사용합니다.
첫 번째 특징은 , A/S 가능! 데이터의 전송이 실패한 경우, 재 전송을 시도합니다.
두 번째 특징은 , 고객 맞춤형 서비스로 수신자의 용량에 따라 데이터 전송 속도를 최적화 합니다.
세 번째 특징은, 불편한데는 없으시고요? 데이터를 전송할 때, 오류를 검사해 데이터가
목적지에 온전하게 도달하도록 보장합니다.
네 번째 특징은, 살짝 느립니다. 바로 아래 나올 UDP 와 비교하면 말이죠.
위와 같은 특징들은 TCP 가 연결형 방식인것을 나타냅니다.
수신자의 상태를 계속 확인하고 개선하려고 합니다.
UDP란?
User Datagram Protocol
속도 제일 !
UDP 는 사용자 데이터 프로토콜의 약자로, 안전성보다는 빠른 속도를 추구합니다.
그 과정에서 데이터가 손실될 가능성 또한 있습니다.
왜냐하면 비 연결형 방식이기 때문에 수신자의 상태를 고려하지 않고
일단 자기 방식대로 다 보내고 보는겁니다.
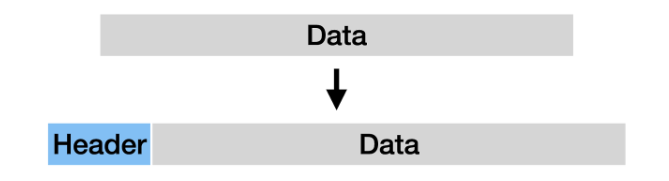
UDP 에서는 데이터 단위를 세그먼트로 쪼개지 않습니다.
그저 header 만 붙여서 보냅니다. 이렇게 data에 header 만 붙인 형태의 데이터 단위를
Datagram 이라고 합니다.
위와 같은 이유로 UDP 는 불특정 다수에게 데이터를 전송하는데 유리합니다.
TCP 같았으면, 일일이 데이터를 잘 받고있는지 계속 통화상태를 유지하려 하지만,
UDP는 비 연결형 방식이기 때문에, 대상이 불특정 다수여도 그냥 보내기만 하기 때문에
훨씬 효율적 이라는겁니다.
이와같은 UPD 의 특징을 브로드 캐스트 라고 합니다 !
UDP 를 사용하여 LAN 에 있는 네트워크 장비에 데이터를 일괄적으로 보낼 수 있습니다.
물론 단점도 존재합니다.
전송 과정에서 데이터가 손상되어도 A/S 를 해주지 않습니다.
데이터를 받는 입장에서는 받은 데이터가 온전한 상태인지도 당장은 알 수 없습니다.
데이터의 전송 순서를 특정하지 않기 때문에, 도착하는 순서 또한 알 수 없습니다.
이러한 UDP 의 특징을 가장 잘 나타내는 활용처는
실시간 영상 전송으로,
데이터가 약간 손실된다 하더라도 크게 문제되지않고, 다수에게 빠르게 데이터를 전송할 수 있기 때문에
UDP 방식이 많이 사용됩니다.
'스탠다드 반' 카테고리의 다른 글
| [스탠다드 반] CS - CPU 란 ? (0) | 2024.10.07 |
|---|---|
| [스탠다드 반]OSI 7계층 - 물리계층 (0) | 2024.09.03 |
| [스탠다드 반]과제 - OSI 7 계층 (1) | 2024.08.28 |
| [스탠다드 반]과제 - 서버 (0) | 2024.08.26 |