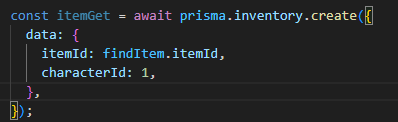
월요일이되고, 가장 먼저 캐릭터 접속 authorization 을
추가로 만든것과 관련한 의견을 튜터님께 물었다.
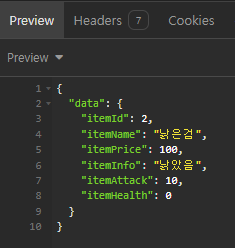
주말 간 진행한 내용으로,
결론만 말하면, 결과는 폭망이다.
오늘은 그 과정에 대한 내용을 서술하도록 하겠다.
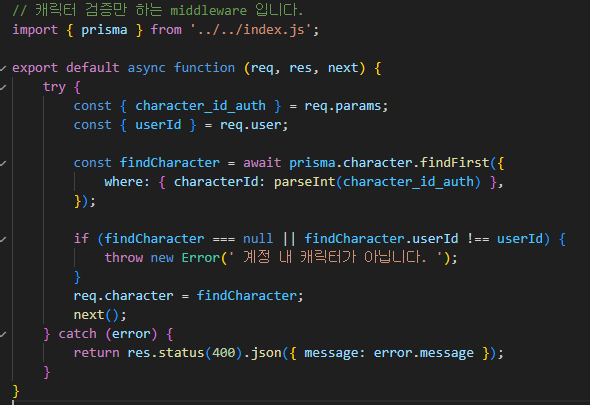
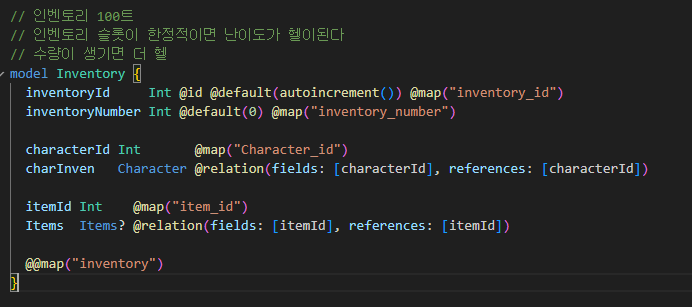
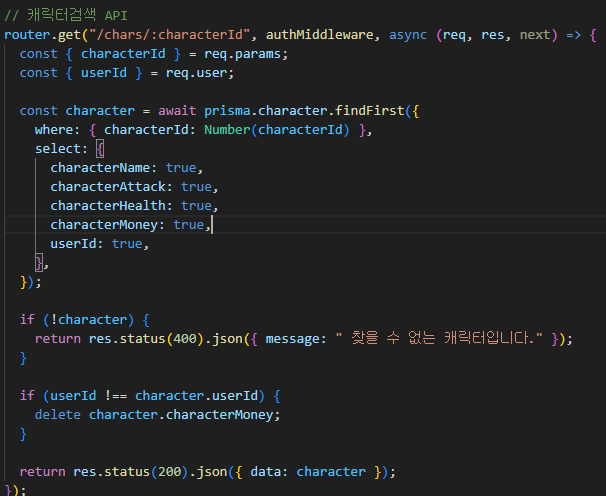
로그인만 인증하는 기존의 authorization (미들웨어) 에 더해서
로그인 + 캐릭터 인증까지 검증하는 authorization 를 추가로 만든 것이고,
이렇게 만든 이유는,
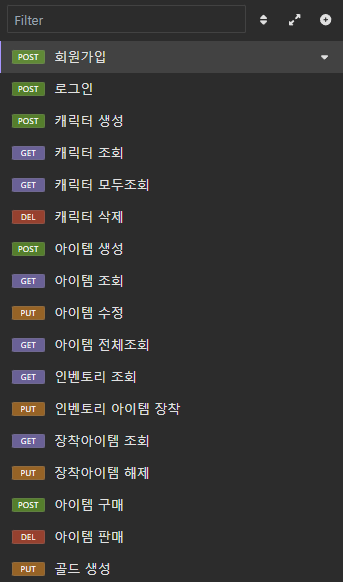
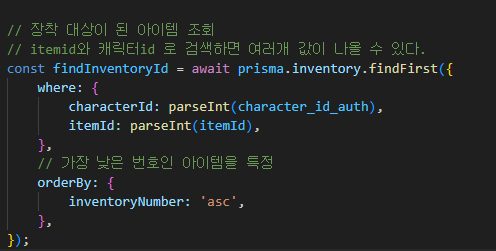
1. 캐릭터 특정이 필요한 상황 (아이템 획득, 구매 등등) 에서 매번 캐릭터id를 param으로 받지 않아도 된다.
-> 캐릭터 인증 (접속) 을 통해 해당 캐릭터 id를 고정할 수 있음
2. param으로 캐릭터Id를 받을 경우 매번 해당 캐릭터Id 가 로그인한 계정에 포함이 되어 있는지
검증을 해야하는데, 그 과정이 캐릭터 접속API에 포함되며,
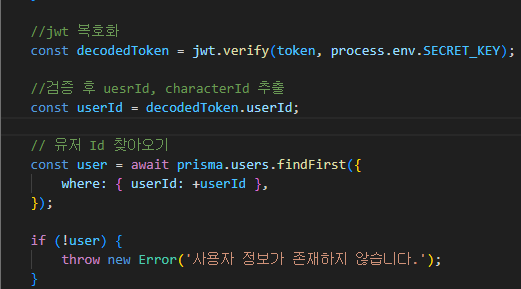
이후로는 JWT 복호화를 통해 검증함으로써 보안에도 유리함.
단점을 따지면,
1. 불필요한 코드일까 ? or 잘못된 접근 방식일까? 하는 막연한 생각 정도?
결론은
단호하게 '안된다' 였고,
해당 코드를 無로 돌릴것을 권장하셨다.
물론, 최대한 부드럽게 말씀해주시긴 했지만,
뭔 쓰잘데기 없는 코드를 만들어왔어? 라고 생각하셨음이 ' 제 6의 감각' 으로 느껴졌다...

코드 복잡성도 늘어나고, 불필요한 실행도 늘고, 유지보수에 대한 문제 등등을 지적하셨다.
납득이 되지 않았다.
과제에서 요구한 방식인 params 로 캐릭터id를 받아도
기존 JWT인증 + 로그인계정에 있는 캐릭터Id가 맞는지에 대한 검증은 해야하기 때문에,
캐릭터Id params를 받는 모든 API에 로그인계정에 있는 캐릭터Id인가- 에 대한 검증 코드가 필요하다.
당연히, 그런 API 는 다수 일 것이기 때문에, 동일한 내용을 복붙을 하거나,
해당 캐릭터 인증만 하는 미들웨어를 어차피 만들어야 할 것이다.
실행할 것이 늘어난다?
1의 내용은 어차피 실행되어야 할 내용 두가지를 합쳤을 뿐이고,
추가적으로 캐릭터 접속 API를 따로 진행해야 한다는 것인데,
그것이 즉시 폐기 라는 대답이 나올 정도로 불필요한 일인지 모르겠다.
오히려 캐릭터 접속API는 캐릭터 검증을 위한 데이터 베이스 조회를 한 번만 하고,
이후로는 JWT 복호화를 통해 진행하므로, 코드 복잡도 면에서 오히려 유리하다.
==> 24.09.10 일 내용 정정
복호화로 얻은 정보를 바탕으로 find를 실행하기 때문에 데이터 베이스 조회 횟수는 같다.
============================================================================
심지어 JWT 복호화는 추가적인 작업이 아니라 기존에 계정Id를 복호화 하던것에 더해진 것이기 때문에,
이부분도 크게 차이가 없다.
물론, JWT 코드 자체가 복잡해질 수 있는 문제는 있다.
내가 놓친 부분이 있을까?
별다른 수가 없다.
일단 피드백 받은 내용대로 갈아엎은 결과와 지금을 비교하는게 최선일듯 하다.
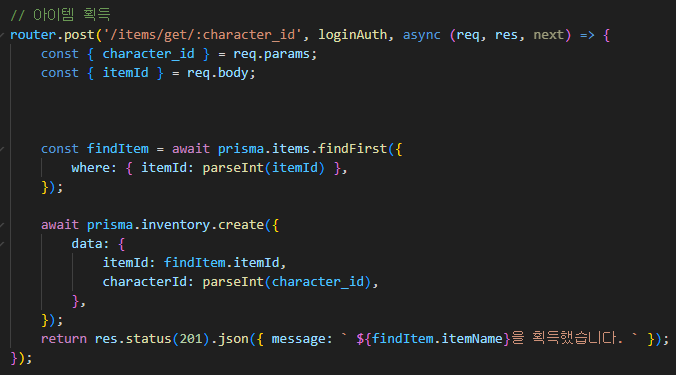
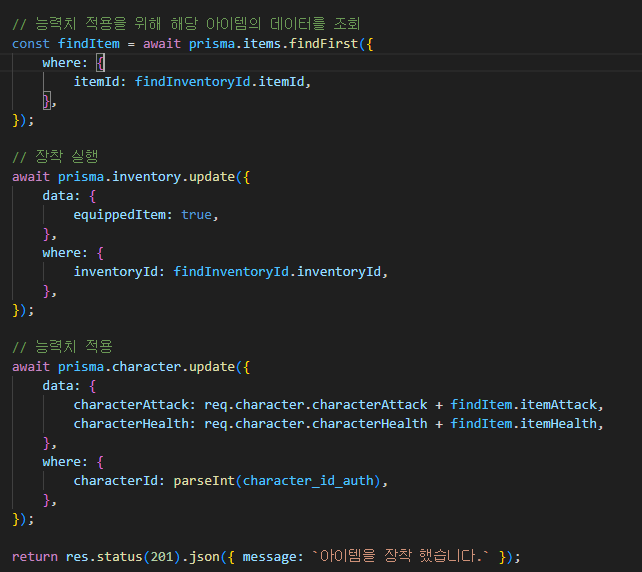
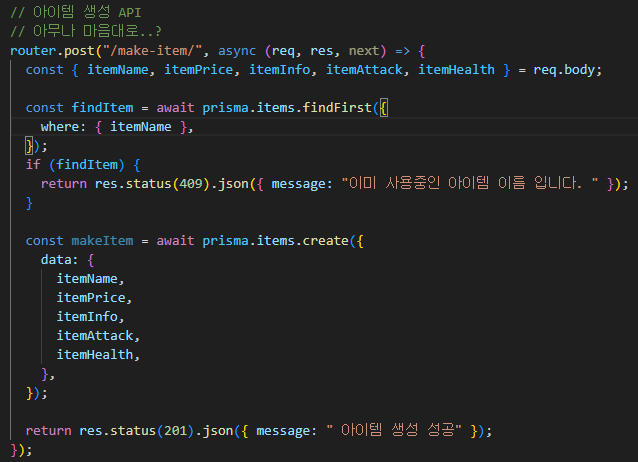
우선 만들어 놓은 아이템 획득 API를 기존의 요구 방식대로 바꿔보자.
위 처럼만 해놓으면, 아무계정이나 로그인해서 모든 캐릭터에 접근 할 수 있으니,
캐릭터 검증 과정이 필요하다.
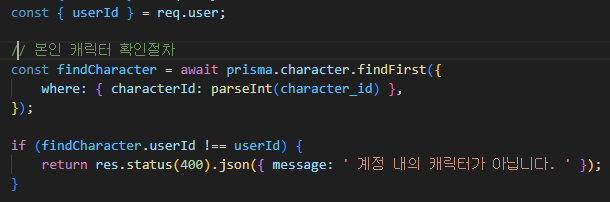
해당 코드를 추가하여, 검증을 하여야 한다.
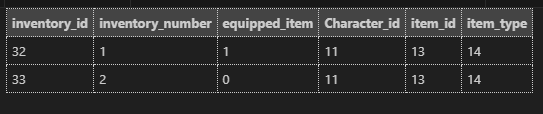
이 과정에서 character.find 조회 과정은 반드시 필요함.
결국, 만들었던 캐릭터 접속 과정은,
기존 로그인 JWT + 저 위에 코드를 합체한 내용일 뿐이다.
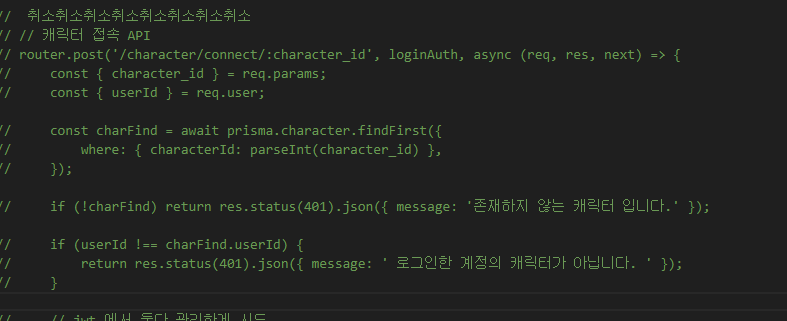 캐릭터 접속 할때 동일한 검증을 한다.
캐릭터 접속 할때 동일한 검증을 한다.
차이는 캐릭터 접속 API를 이용해야 한다는 점...
이 과정 자체가 문제일까?

JWT에 추가로 characterId 가 들어가기 때문에 JWT 토큰이 무거워진다는 단점도 있을 것이다.
차라리,
늦게 확인한 것은 안타깝지만 해당부분은 과제 요구사항에서 벗어나기 때문에 안된다.
라는 대답이 돌아왔다면 머리가 아프진 않았을텐데...

심란하다
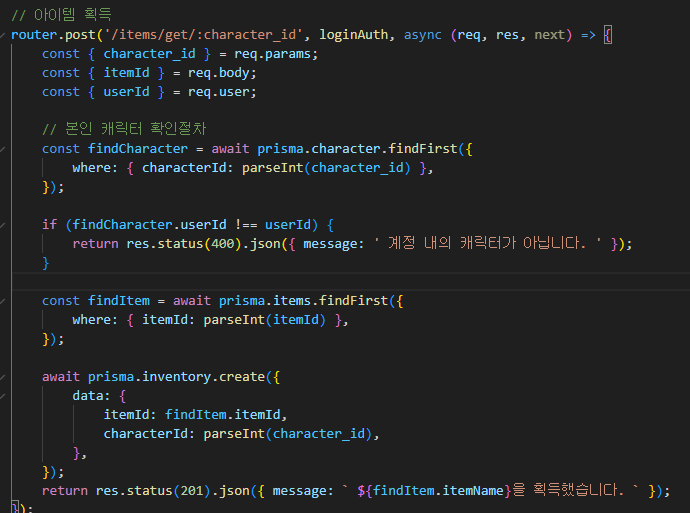
그렇게 바뀐 아이템 획득 API 이다.
본인 캐릭터 확인 절차는 따로 미들웨로 만들기엔 좀 짧지 않나 생각도 들고...
그냥 복붙 해서 쓰자니, 유지보수가 어려워진다.
해결방안?

만약, 캐릭터 검증이 필요한 API 의 경우, _auth 가 더해진 param을 받아서
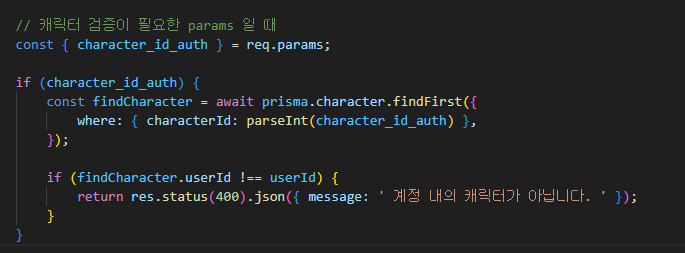
기존 로그인 미들웨어에 해당 구문을 추가하여, character_id_auth 를 param으로 받은 경우에만
검증을 진행하도록 했다.
물론 이 해결방안도 상당히 짜치는 구조이다.
굳이 login 검증만 하던 미들웨어에, 조건 한정으로 캐릭터검증을 하는 일을 부여했으니 말이다.
말하자면,
때에 따라 캐릭터 검증도 하는 유능한 login 검증 미들웨어가 아니라,
이걸 왜 나한테 시키지? 라는 상황의 login 검증 미들웨어가 된것에 가깝다.
login 검증 미들웨어가 실행 되면, 반드시 character_id_auth 의 존재를 체크해야 하고,
필요없다면 undifined를 정의한채로 넘어가는 불필요한 동작이 생긴 것이다.
해결방안의 해결방안?
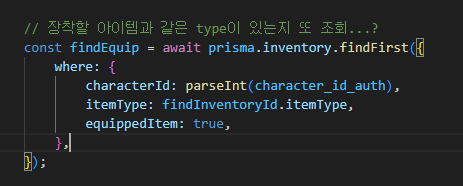
1. 비록 긴 코드는 아니지만, 캐릭터 검증만을 위한 미들웨어를 만든다.
폐기된 코드가 떠오르는 방안이지만, 엄연히 차이가 있다.
폐기된 코드 => 기존 A 작업 + 새로운 B 작업 을 합쳐놓은 C작업을 만든것이고,
해당 방안은 => 새로운 B작업만 만들고, 필요에 따라 A 와 B를 각각 호출하는 것이다.
그런데B가 실행되는 상황에서는 반드시 A도 실행되어야 하는 상황인데..?
그래서 A+B 를 합친 C를 만들었던 것인데....??

여기서, 의문이 들었던 부분을 추가로 짚고 넘어가보자..
JWT 인증 + param으로 characterId를 받는 상황이라면,
해당 API는 전부 캐릭터 검증을 추가로 해야한다는건 이미 여러번 설명한 내용이다.
그렇게 되면 캐릭터 인증만하는 미들웨어를 추가하던지, API 마다 검증하는 코드를 붙여넣던지 간에,
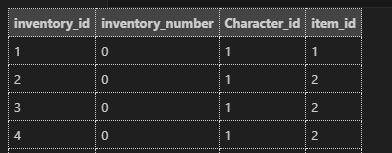
character 데이터 베이스를 조회해야 한다. API가 실행될 때마다 find를 통해, character Id를 찾아 검증해야 하기 때문이다.
폐기된 방법 ( 캐릭터 접속 API를 만들고, 로그인검증+캐릭터검증에 해당하는 미들웨어를 추가) 의 경우,
기존에 있던 로그인 검증과 동일하게, 캐릭터 접속 당시에만 데이터 베이스를 조회하고
문제가 없을경우 JWT를 발급해서, 이후 발생한 검증은 발급한 JWT를 복호화를 통해 진행되기 때문에,
보안적인 면에서도 유리하고, DB조회도 접속시 1회만 하면 되기 때문에 복잡도 면에서도 유리하다.
==> 24.09.10일 정정
DB 조회는 미들웨어에서도 진행하기 때문에 미들웨어 호출당 1회의 조회를 하게 됨
또, 한번의 접속으로 캐릭터를 계속해서 특정할 수 있기 때문에,
클라이언트가 API 마다, 캐릭터id 를 param으로 전달해줘야 하는 일도 없어진다.
나는 틀리지 않았다
라는 말이 하고싶은것이 아니다.
어디가 잘못된건지 아직도 모르는것이 화가난다

폐기된 코드에 대한 이야기는 그만 하도록 하자.
다시 다음 방안으로 넘어가서,
2. 튜터님의 피드백에 해당하는 내용으로 ,
login 검증 함수를 호출할 당시에, 미리 캐릭터 검증을 포함하는지, 안하는지 정보를 줘서
검증이 필요 없을때는 본래의 코드만, 정보가 있을 때에는 추가 코드를 실행하게 만들어서
각각 온전하게 필요한 부분만 작동이 가능하도록 하는 방법 에 대한 내용이다.
이 방법은 내가 당장 이해하기엔 어렵지 않을까 생각이된다.
분노의 TIL 을 작성하다 보니, 오늘 진행한 내용은 결국 작성하지 못했다.
다음 시간에 !!