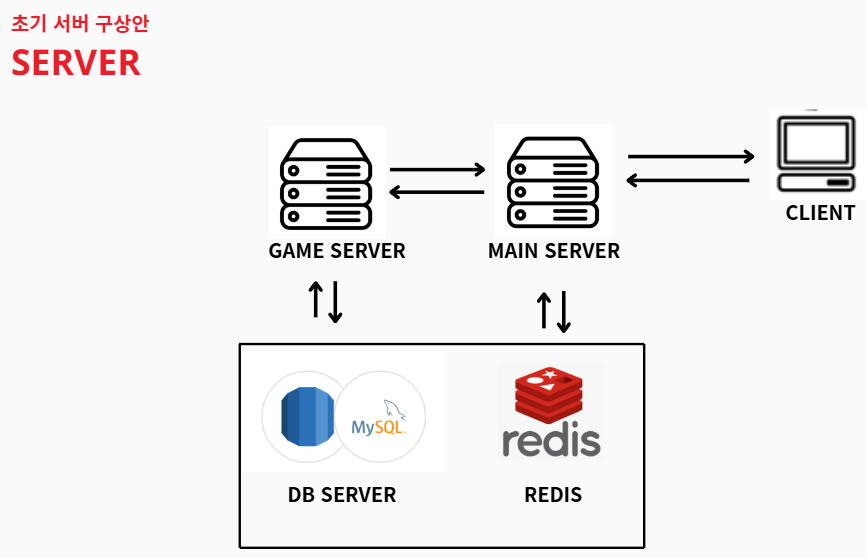
- 최종 프로젝트 -

로깅 시스템

최종 프로젝트에 ELK 로깅 시스템을 적용해보기로 했다.
본문의 내용은 전부 프로젝트에 적용한 내용을 바탕으로 작성하였다.
ELK 란?
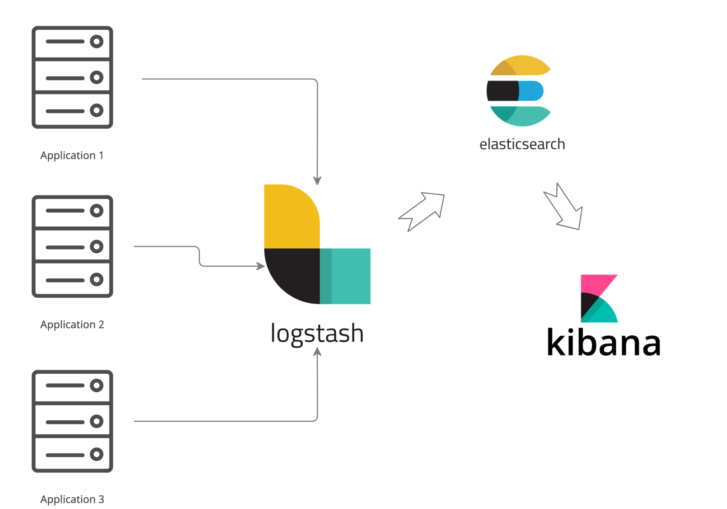
Elastic search , Log stash , Kibana 로 구성된 로깅 시스템을 말한다.
Log stash
각 서비스에서 발생하는 log 를 logstash 로 수집하고,
logstash 는 수집한 log를 elastic search 에 전달한다.
이 과정에서, log stash 는 비정형의 데이터 또한 원하는대로 가공하여
전송할 수 있으며,
그 과정은 Input (입력), Filter (가공) , Output (출력) 크게 세 부분으로 구성된다.
input {
beats {
port => ****
}
}
Input 부분에서는 크게는 Port 를 지정하여 데이터를 받고,
필요에 따라 Codec 을 지정하여 Json, Html 등 구조화된 텍스트 또한 쉽게 처리하고 저장할 수 있다.
filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:timestamp} \[%{WORD:label}\] \[%{WORD:level}\]: %{GREEDYDATA:log_message} %{GREEDYDATA:extra}"
}
}
}
Filter 는 Log stash의 강력한 핵심 기능으로, 어떤 형태로 데이터를 받던지 간에
원하는 형태로 재 가공하여 데이터를 저장할 수 있다.
설정에 따라 그저 string 이었던 데이터도 규칙을 만들어서 필드를 구분하거나,
필요가 없는 부분을 가공 또는 제거 하는 등 다양한 작업이 가능하다.
output {
elasticsearch {
hosts => "elasticsearch:9200"
user => "****"
password => "****"
index => "logs-%{+yyyy.MM.dd}"
}
stdout {
codec => rubydebug
}
}
Output 에서는 가공한 데이터를 어디로 보낼것인지, 즉 출력을 정하는 부분이다.
일반적으로 Elastic search 가 output 이 될 것이며,
해당 부분에 Elastic search에 관한 내용을 기재하게 된다.
추가적으로 ,
stdout 에서 가장많이 사용하는 rubydebug 는
logstash 에서 데이터를 받았을 때, 해당 내용을 logstash 의 log 에 남길 수 있다.

Elastic Search
엘라스틱 서치는 루씬 기반으로 개발된 검색 엔진이자 저장소 이다.
ELK 구성에서는 log stash 가 전달한 데이터를 저장하며,
이 수많은 데이터 (log) 에서 원하는 데이터를 빠르게 찾을수 있도록 구분하고 검색하는것이
엘라스틱 서치의 주요 기능이다.
엘라스틱 서치는 기본설정만 해도 알아서 잘 작동하기 때문에
기본 설정들 외에는 건들지 않았다.
Kibana
대미장식인 Kibana 는, Elastic 에서 제공하는 데이터 시각화 툴로,
엘라스틱 서치에서 색인된 데이터를 검색하고 시각화 하는 하는 기능을 제공한다.
Discover

기본적으로 데이터를 elasticSearch 가 받은 그대로 다소 지저분하게 확인 할 수 있으며,

필드로 구분하여 원하는 필드의 데이터만 확인 할 수도 있다.

여기에 더해 Dash board 를 통해
데이터를 표본삼아 그래프화 하는 등, 여러가지 시각적으로 데이터를 표현할 수 있다.


그러면, Log stash 는 어떻게 data를 수집하는가
프로젝트 초기부터, winston 을 통해 log를 생성했는데,
마침 winston-logstash 라는 모듈을 통해
log stash로 로그 전송이 가능하다는것을 알게되어 적용해보았다.
const logstashTransport = new LogstashTransport({
host: host,
port: port,
}); // Logstash로 로그 전송
위 코드를 로그 생성하는 부분에 넣어주면, 로그 생성과 함께 해당 로그를 logstash 에 전송한다.
elk 구성만 잘 되어있다면, 간단한 코드 수정으로 바로 log 를 보낼 수 있기 때문에
접근성이 뛰어났다.
그러나 여러가지 부분에서 크고 작은 문제가 계속 발생했다.
트러블 슈팅 = 로그 수집
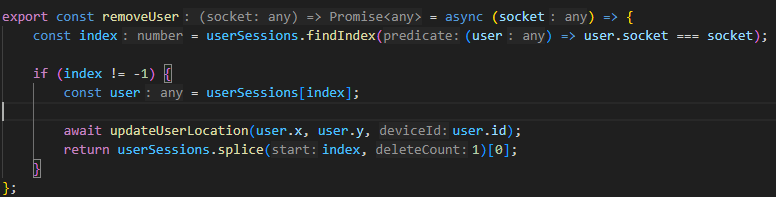
문제 1. 프로젝트는 MSA 구성이다.
해당 모듈은 로그를 생성하는데 이어서, 해당 로그를 전송하는 모듈이기 때문에,
로그 생성부분에 부착이 된다고 볼 수 있다.

현재 프로젝트는 MSA 이고, 로그가 발생하는 서버가 10개 이므로...
10개의 서버가 winston-logstash 를 사용하여 logstash 와 TCP 연결을 맺게 되고
각각의 서버에서 로그가 발생할 때마다 log를 무작정 마구마구 보내게 된다.
데이터가 손실될 우려는 적지만, 연결이 많아질 수록 성능이 저하될 수 밖에 없고,
log 를 생성하는 각각의 서버에서도 부담이 가게 된다.
문제 2. 알 수 없는 syslog 의 발생 ??
해당 문제는, 결국 winston-logstash 모듈을 버리게 된 계기로,
logstash 에서 전송받은 message 를 확인 할 때
난데없이 syslog 형태의 데이터가 삽입되는 문제가 발생했다.
message:<30>Dec 18 17:10:11 app-logs[89717]: [ serializeForGate ] data ===>>>: { sessionId: '0c2e5d1e-f234-4f3e-a0cd-2dde306aa2b9' }
메세지 앞부분에 출처를 알 수 없는 syslog로 추정되는것이 삽입되어있는것을 확인했다.
이로 인해 데이터를 json 으로 정형화 하는것에도 방해가 되어 에러가 발생했고,
애초에 syslog는 내게 필요하지 않은 데이터이다.
로그를 생성하고 보내는 부분에서 확인해보아도
"message": "[ serializeForGate ] data ===>>>: { sessionId: '0c2e5d1e-f234-4f3e-a0cd-2dde306aa2b9' }"
syslog 의 흔적을 찾아볼 수없었고,
그렇다고 log stash input에서 syslog 를 설정한 것도 아니었다.
더욱 이해가 안가는 부분은,
pm2로 서버를 띄우면 syslog 가 안붙어있고 Docker 로 띄우면 syslog가 달려있다는 것이다.
해결 방법 = Filebeat 로 선회
도... 도망이 아니다 !!

위의 에러를 원인을 찾지 못했지만, 원래 Filebeat를 사용하려고 했던 계획이 있었기 때문에,
만약 Filebeat 를 사용해도 동일한 문제가 발생한다면 그 때 가서 해결하려고 했다.
파일 비트는 위 모듈을 사용했던 형식과 다르게, 중앙 집중식 로깅을 적극적으로 활용할 수 있다.
기존 서버들은 각각의 Docker 컨테이너로 구성되며,
모든 하위 서버는 호스트 서버의 /logs 폴더를 볼륨화 하여 사용하기 때문에
모든 로그는 호스트서버의 logs 에 저장된다고 할 수 있다.
Filebeat 는 마찬가지로 볼륨화 한 logs 폴더를 바라보고, log의 변화를 체크하면 된다.
전반적으로 잘 작동하며, 위에서 발생한 정체불명의 syslog 문제는 발생하지 않았다.

다만, 위와 같이 기록된 log의 경우 한 줄, 한 줄 message 를 따로 보내게 되기 때문에
알아보기도 어렵고 불필요하게 작업량이 늘어나게 된다.
위의 log 또한 사람 보라고 만들어진 log 이니 만큼, 기록되는 방식을 가공하기 보다는
일단 통째로 한번에 보내고, log stash에서 가공하는것이 알맞은 흐름이라고 생각했다.

filebeat.yml 파일에서 multiline 을 통해 적절히 내용을 병합하여 전송하고,
filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:timestamp} \[%{WORD:label}\] \[%{WORD:level}\]: %{GREEDYDATA:log_message} %{GREEDYDATA:extra}"
}
}
}
위에서 봤던 그 필터를 logstash.conf 에 적용해 주면,
설정한 대로 field 를 구분할 수 있게 되고,
그 구분한 필드를 바탕으로 내용을 정렬한다면, 본문 상단에서 확인했던 형태로
log를 조회 하는것이 가능해진다.
syslog의 원인은 찾지 못해 아쉽지만,
filebeat 가 일을 잘 해줘서 다행이다.