
[수업 목표]
- 데이터에서 예상하지 못한 값이 나왔을 때 (이상한 값, 값이 없음 등), 분석에 적절하에 처리한다
- SQL 로 엑셀에서 자주 사용하는 형태로 데이터를 만든다
- 업무에 활용할 수 있는 다양한 SQL 심화 문법을 익힌다
오늘은 SQL 을 학습하기로 했다.
시작은 복습부터
저번 시간에, 배웠던 내용은 Subquery 와 Join 이다.
Subquery는
한번의 select from 문으로 나온 결과에 이어서 추가적인 연산을 하거나 재 활용할 때 사용한다.
Select ****
from
(
selct *
from **
) main_query와 같이 쓰여진다.
Join은
두 개 이상의 테이블을 결합 할 때 사용하며, 형태에 따라 Left join / Inner join 을 사용할 수 있다.
select ABC
from table1 t1 left join (또는 inner join) table2 t2 on t1.공통컬럼 = t2.공통컬럼
오늘 새로 배울 내용은
1. 조회한 데이터 값이 이상하다?
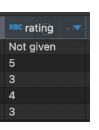
rating 컬럼에 Not given 이라는 어울리지 않고 연산에 방해되는 데이터가 존재한다.
(이러면 데이터 베이스부터 고쳐야 하는게 아닐까 라는 생각이 문득..)
만약 avg 를 이용하여 평균값을 구해야 하는 경우, not given 을 0으로 계산하여 전부 나누기 때문에
의도하지 않는 계산 결과가 나올 수 있다.
만약, not given 으로 표기된 데이터를 제외하고 나머지만의 평균을 구하고 싶다면,
avg(if(rating <> 'Not given', rating, null)) not_given_del위처럼 if 구문으로 rating 내의 Not given을 null 처리 해줄 수 있다.
값이 null 인 경우 연산에 포함하지 않는다
2. 다른 값으로 대체하기
데이터를 조회했을 때, 원하지 않는 데이터를 대체하여 사용하는 방법이 있다.
1) null 을 다른 데이터로 대체
이 경우엔 coalesce 문이 사용된다.
coalesce(컬럼명, 대체값)
위 방법으로 컬럼내의 null 값을 전부 대체값으로 대신할 수 있다.
2) 조건문을 이용하여 대체
if 문은 슬슬 익숙 해 질 때가 됐다.
if(age < 50 , age, 대체값)if문을 사용하여 원하지 않는 값 (특히 일정 범위를 벗어난 값)을 대체 표시 할 수 있다.
3) 위와 비슷하게 사용할 수 있는 것으로,
case when 구문이 있다. 마찬가지로 이전에 봤던 함수다.
select customer_id, name, email, gendor, age,
case when age<15 then 15
when age>80 then 80
else age end "범위를 지정해준 age"
from customers
상식적이지 않은 데이터를 수정할 때, 특히 데이터의 상, 하한을 임의로 지정하고 싶을 때 사용하면 좋다.
다음은. SQL 로 Pivot Table 만들어보기

액셀에서 자주 봤던 형태의 table 로
데이터를 집계하여 기준에 따라 보기 쉽게 배열하는것이 목적인 테이블이다.
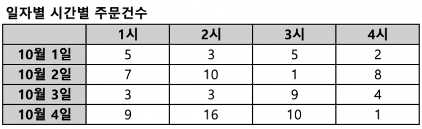
위와같은 형태의 Pivot table 을 만들어 보자.
우선, 음식점별, 시간별 주문건수를 집계한다
select a.restaurant_name,
substring(b.time, 1, 2) hh,
count(1) cnt_order
from food_orders a inner join payments b on a.order_id=b.order_id
where substring(b.time, 1, 2) between 15 and 20
group by 1, 2이전에 배운 내용으로 작성이 가능
select restaurant_name,
max(if(hh='15', cnt_order, 0)) "15",
max(if(hh='16', cnt_order, 0)) "16",
max(if(hh='17', cnt_order, 0)) "17",
max(if(hh='18', cnt_order, 0)) "18",
max(if(hh='19', cnt_order, 0)) "19",
max(if(hh='20', cnt_order, 0)) "20"
from
(
select a.restaurant_name,
substring(b.time, 1, 2) hh,
count(1) cnt_order
from food_orders a inner join payments b on a.order_id=b.order_id
where substring(b.time, 1, 2) between 15 and 20
group by 1, 2
) a
group by 1
order by 7 desc작성한 내용을 pivot table 형태로 바꿔주는 구문이다.
기본적으로 이전 데이터를 활용하여 subquery를 만들어주고
hh로 명명한 주문시간 (substr 로 시간에 해당하는 앞의 두자리만 추출)별로 cnt_order의 숫자를 카운트 ... 하고 !
subquery 에서 다시 가져와서 restaurant_name , hh 시간별로 추출한 것을 각각 표기... 하고 !
restaurant_name 을 그룹화 해서 정렬 ... 을!
hh='20' 기준으로 역순나열 이라고 해석 할 수 있다

사실 좀 실망인데,
Pivot table 을 위한 함수가 있는게 아니라
수동으로 pivot table이 되도록 때려박는 것이었다.
Pivotmax cnt_order, hh(15, 16, 17, 18, 19, 20) 이런걸 기대했는데
혹시 나중에 알려주실려고 그런지 모른다.
남은 시간은 다른 pivot table 을 보면서 자습해야겠다.
'사전캠프' 카테고리의 다른 글
| 14일차 - 액셀보다 쉽고 빠른 SQL (0) | 2024.07.09 |
|---|---|
| 13일차 - 알고리즘 풀이 (0) | 2024.07.08 |
| 11일차 - 알고리즘 풀이 (1) | 2024.07.03 |
| 10일차 - [왕초보] 웹개발 종합반 (1) | 2024.07.02 |
| 9일차 - [왕초보] 웹개발 종합반 (0) | 2024.07.01 |